
Spun content used to be a nuisance back in the days when search engines weren’t so smart. It still is today, to some extent at least.
People would reuse a single article/blog post across several of their Tier 1 or Tier 2 Web 2.0 properties by using content spinning tools.
A lot of content on the web as a result, especially before ~2016, is full of spun articles. We rarely, if at all, come across those content, thanks to the smart search engines we have today.
However, for a project I was working on, I had to filter out all such articles which were meaningless or computer generated.
So full disclaimer, you probably won’t be able to get 90% accuracy using this n-gram analysis method, and there might be some or many false positives depending on the content you are dealing with.
There are some new content spinners that only replace a few words or replace them intelligently, instead of naive synonym substitution. For these, this method won’t give you the best results.
For my use case though, this method was more than enough, your mileage may vary.
What is an n-gram ?
An n-gram is a contiguous sequence of n items from a given sample of text or speech (Wikipedia). We are going to be working with trigrams, which are a sequence of 3 contiguous items.
Overview
You first, build a huge JSON model, scraping web pages and extracting well-written articles from them. (I have already done this and will be providing a link to download it below.)
You then process these scrapped articles to create a JSON Dictionary with each trigram as keys, and the number of times it has occurred (its frequency) as a value.
So if you had a sentence like Mary had a little lamb and Mary had a big cat, the JSON would look something like:
{
"Mary had a": 2,
"had a little": 1,
"a little lamb": 1,
"little lamb and": 1,
"lamb and Mary": 1,
"and Mary had": 1,
"had a big": 1,
"a big cat": 1
}
This was for a simple sentence, however, the model we will be using is built on over 300 million+ words.
The raw corpus is ~2GB in size, however, after some preprocessing and filtering, we can filter out statistically insignificant trigrams with frequency < 5. The processed JSON model, as a result, is comparatively smaller at around 60MB in size.
Once you have the JSON model, you are all set to classify the content you want to test as spun or not.
The way this works is - you get the content, extract all the trigrams in that article. You then calculate the percentage of how many trigrams are available in our model.
Now all you need is to set some threshold on the percentage to classify them as spun or original. The code and detailed explanation of all this is given below.
Getting the web corpus n-gram model
You can download the n-gram model, we will be using from here - Download web corpus n-gram model.
Classifying Content
The code in this guide is written in ruby, but it should be easy enough to follow and convert it to your language of choice.
Load our Model
require "json"
model = JSON.parse(File.read("./web-corpus-trigrams.json"))
Get the text you want to test as a string
Here the text is a paragraph from a human-written, New York Times article.
text_string = "In Houston, the gleaming Galleria Mall was open again, but not all of its stores, and the ample, close-in parking suggested some customers were wary of returning. In Mobile, Ala., a venerable boutique decided to reopen with one dressing room, so it could be disinfected between uses. And in Galveston, Tex., beachgoers returned to the shore."
Extract tokens from text
Get all tokens from the text (character sequences like words excluding spaces)
tokens = text_string.scan(/\w+|[^\w\s]+/)
Get all trigrams from tokens
To get the trigrams from the tokens array, we need to consider every 3 consecutive elements as a trigram.
We can do this with the help of Ruby’s each_cons method.
We then use the uniq method to get only unique elements from the array.
trigrams = tokens.each_cons(3).to_a.uniq
Get count of matched trigrams
Now we need to check how many trigrams we have from our text string exists in our JSON model.
matched_trigrams = 0
trigrams.each do |trigram|
# trigram is an array of 3 words, join them by a space to match against our model
trigram_string = trigram.join(" ")
# if the trigram string exists in our model increment count of matched_trigrams
if model[trigram_string]
matched_trigrams += 1
end
end
Get the number of characters in our text
We then get the no of characters in our text, (we use tokens because we don’t want to count the whitespace characters).
total_characters_in_tokens = tokens.sum {|token| token.length}
Calculate score
Now, calculate the score of our text.
score = matched_trigrams/total_characters_in_tokens.to_f
We divide by the total_characters_in_tokens to make it a normalized score across texts of varying lengths.
A higher score in principle means that the article is probably human written, while a lower suggests otherwise.
Result
The text we used above returns a score of 0.08391.
We spin the text we used to get the following text.
text_string = "In Houston, the shining Galleria Strip shopping center was started once more, at any rate is neither the entire of its physical holding compartment, and the exceptional, close-in apex proposed a two of clients were cautious about coming to back. In Dynamically minute, Ala., a respected flower seller chose to again establish with a one influencing an area, so it could be cleaned between occupations. In like manner, in Galveston, Tex., beachgoers return back to the shore."
The score for this spun text is 0.06281. A difference of ~28%.
Now, not all results are going to be like this. Some spinners are more intelligent than others and so you might get varied results.
Here is an image showing the results when executed on a larger testing set. Red ones are spun/meaningless while the green ones are human written.
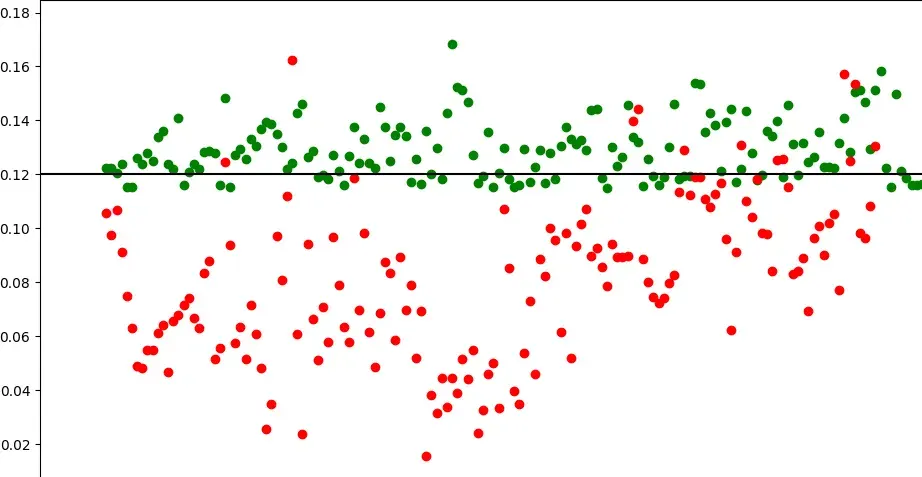
As you can see, there are a few false positives as well as many false negatives.
Setting a threshold
This usually varies from domain to domain, as well as the level of confidence you want in false negatives. The black line in the above image is where (0.12) I set my threshold to.
I am okay with getting many false negatives, but false positives (bad text appearing to be good need to be minimal).
Similarly, your use case may vary and you may need to adjust the threshold accordingly.
There’s more…
There are also many other techniques that can be used in conjunction with this simple n-gram statistical analysis.
One such is Parts of Speech tagging your entire text. Getting the ratio of all the various parts of speech tags and looking for significant variations from the mean.
I, however, did not have much success with that and chose not to use it. It might work wonders for the kind of content you are classifying, or not.
If you have any questions, feel free to reach out to me on twitter (@owaiswiz).
Full Code
require "json"
model = JSON.parse(File.read("./web-corpus-trigrams.json"))
text_string = "In Houston, the shining Galleria Strip shopping center was started once more, at any rate is neither the entire of its physical holding compartment, and the exceptional, close-in apex proposed a two of clients were cautious about coming to back. In Dynamically minute, Ala., a respected flower seller chose to again establish with a one influencing an area, so it could be cleaned between occupations. In like manner, in Galveston, Tex., beachgoers return back to the shore."
#Get all tokens from the sentence (character sequences like words excluding spaces)
tokens = text_string.scan(/\w+|[^\w\s]+/)
trigrams = tokens.each_cons(3).to_a
matched_trigrams = 0
trigrams.uniq.each do |trigram|
# trigram is an array of 3 words, join them by a space to match against our model
trigram_string = trigram.join(" ")
# if the trigram string exists in our model increment count of matched_trigrams
if model[trigram_string]
matched_trigrams += 1
end
end
total_characters_in_tokens = tokens.sum {|token| token.length}
score = matched_trigrams/total_characters_in_tokens.to_f
puts score
Get more articles like this
Subscribe to my newsletter to get my latest blog posts, and other freebies like Treact, as soon as they get published !